TÜRKİYE TÜRKÇESİ VE URAL-ALTAY DİL GRUBU DİLLERİNİN KARŞILAŞTIRILMASI
Etimolojik araştırmalarda
dillerin akrabalığını araştırmak önemli bir yer tutar. Bunun için birçok
inceleme yöntemi uygulamıştır. Bunlardan en çok geçerli görülenlerden bir
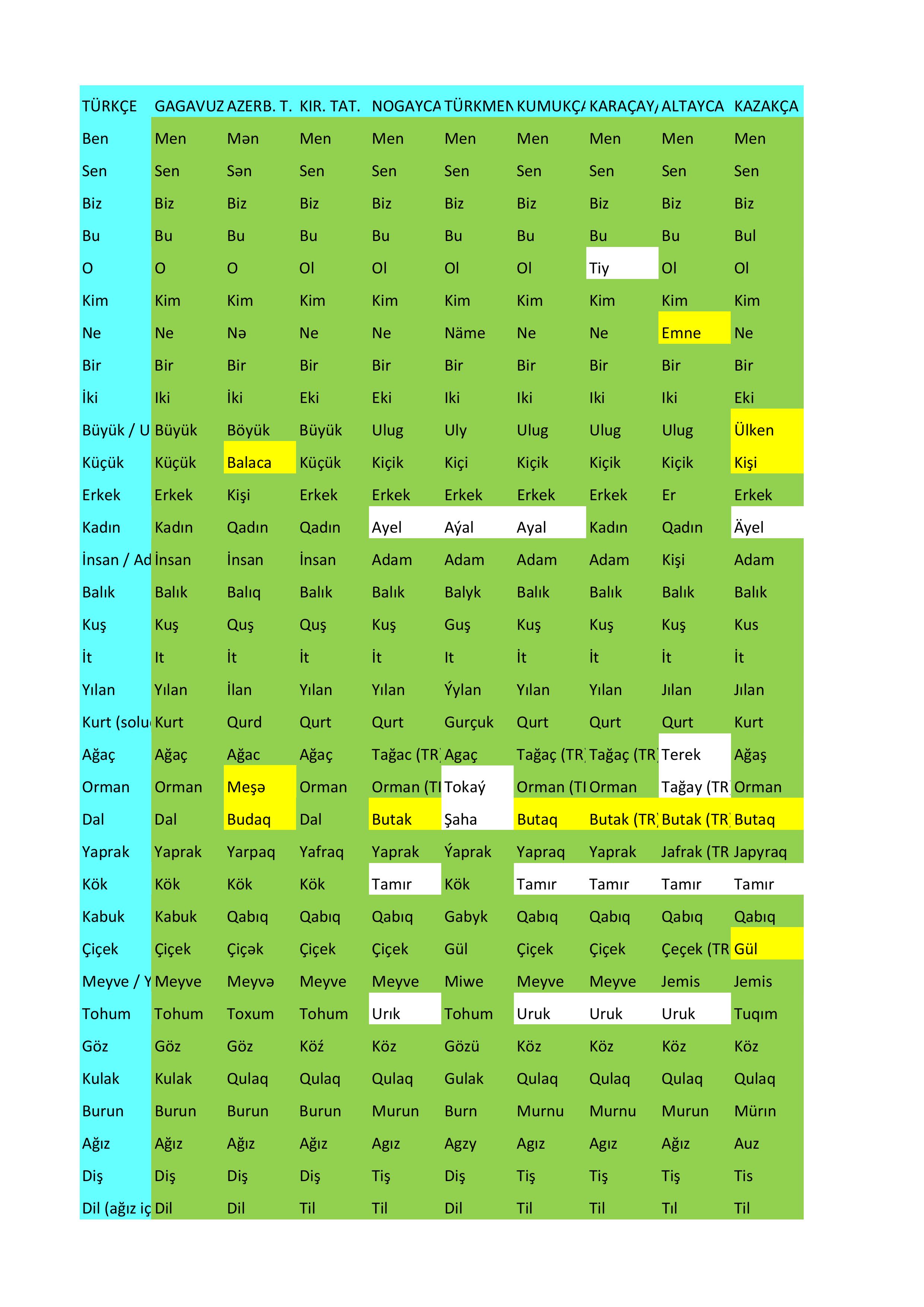
tanesi Morris Swadesh tarafından geliştirilen Swadesh Listesidir. Bu yöntemde
bir dilin en temelinde yer alan, en basit 100 kelime seçilir, bu kelimeler
açısından diller birbiri ile karşılaştırılır ve yakınlık derecesi ortaya konur.
Öncelikle söyleyeyim bu bilimsel
bir çalışma değildir.
Türkçe, dil ve dil tarihi
konularına ilgim olduğu için Türkçe ve diğer Ural-Altay dilleri arasındaki
yakınlıklar hakkında az buçuk bilgim ve ön görülerim var. Merakım ise şuydu:
Ben de bu Swadesh yöntemini uygulayarak Türkiye Türkçesi ile diğer dillerin
yakınlıklarını ortaya koyduğumda çıkan sonuç genel bilgimle örtüşecek mi
örtüşmeyecek mi?
Bu yöntemi uygularken Chatgpt’yi temel
kaynak olarak kullandım. Akademik bir çalışma olmadığını belirtmiştim. Malum Chatgpt
her zaman doğruyu söylemiyor hatta bazı, sırf cevap vermiş olmak için
durumlarda kendisi kelime bile uydurabiliyor. Böyle durumlarda onu biraz daha
sıkıştırmak ve yönlendirmek gerekti.
Çıkan sonuçları Google Translate
ile de kontrol ettim. İnternet üzerinde bol kaynak bulunan Kazakça, Kırgızca,
Azerbaycan Türkçesi vs gibi dillerde Chatgpt’nin neredeyse tamamen doğru
sonuçlar verdiğini gözledim.
Ama Başkurtça, Sahaca ve
Çuvaşçada farklılıklar çoktu ve bu dillerin değerlendirmesinde hem Chatgpt’yi
hem de Google Translate’i eş oranda değerlendirdim. Bu nedenle tablolarda bu
dillere ayrılmış iki sütun göreceksiniz.
Gagavuzca beni en çok
zorlayanlardan biri oldu. Chatgpt bu dilde bilmediği bütün kelimeleri Türkiye
Türkçesi ile doldurdu. Google Translate’e göre ise böyle bir dil yok! Gagavuzca
için bütün kelimeler için tek tek akademik yayınları taradım ve oralardan
aldım. Yani çalışmamın en bilimsel sütunu Gagavuzca J.
Karaimce için ise neredeyse hiçbir
kaynak bulamadım. Bulabildiğim sınırı sayıdaki akademik kaynaklar listemdeki çok
az sayıda kelimeyi içerdiği için yeterli olmadı. Ve Karaimceyi çalışmamdan
çıkarmak durumunda kaldım.
Karşılaştırdığım dildeki kelimenin
bizim için anlaşılabilirliği ve köken birlikteliğine göre kimisine tam puan
(yeşil hücreler) kimisine yarım puan
(sarı hücreler) verdim.
Chatgpt’nin bana en başta
önerdiği kelimeler arasında 2 adet yüzmek fiili olmasından ve karıştırılabileceğinden
dolayı “to swim” anlamındaki yüzmek fiilini tuttum, diğerinin yerine yine temel
bir fiil olan doğmak fiilini koydum.
Sonuçlar beni yanıltmadı ve dil
yakınlıkları ile beklentimi büyük oranda doğrulamış oldum. Ama Başkurtçanın ve
Kazakçanın dilimize beklediğimden daha yakın, Moğolcanın ise biraz daha uzak olduğunu
gördüm.
Ayrıca Japonca ve Koreceyi en
azından Fince ve Estoncadan daha yakın çıkar diye bekliyordum ama öyle olmadı. Tabi
bunun benim yöntem ve bilgi hatamdan olmuş olabileceğini göz ardı etmemek
gerekir.
Ve çıkan sonuçlara göre Türkçe ve
ilgili diğer dillerin yüzdesel olarak yakınlıkları:
|
GAGAVUZCA |
% |
97,5 |
|
AZERB. TÜRKÇESİ |
% |
96,5 |
|
KIRIM TATARCASI |
% |
94 |
|
NOGAYCA |
% |
85 |
|
TÜRKMENCE |
% |
84 |
|
KUMUKÇA |
% |
83,5 |
|
KARAÇAY/BALKARCA |
% |
81,5 |
|
ALTAYCA |
% |
81 |
|
KAZAKÇA |
% |
76,5 |
|
ÖZBEKÇE |
% |
75,5 |
|
UYGURCA |
% |
73,5 |
|
KIRGIZCA |
% |
71,5 |
|
TATARCA |
% |
70,5 |
|
BAŞKURTÇA |
% |
52 |
|
SAHACA |
% |
30 |
|
HAKASÇA |
% |
28 |
|
ÇUVAŞÇA |
% |
7,5 |
|
MOĞOLCA |
% |
4 |
|
MANÇUCA |
% |
3,5 |
|
MACARCA |
% |
2,5 |
|
FİNCE |
% |
2 |
|
ESTONCA |
% |
2 |
|
JAPONCA |
% |
1,5 |
|
KORECE |
% |
0,5 |








Yorumlar
Yorum Gönder